Лингвисты ТГУ создают оптимальную модель риск-коммуникации
Ограничения привычного образа жизни человека в период пандемии привели к большому числу неконтролируемых потоков информации, зачастую некорректной и недостоверной. Лингвисты ТГУ решили изучить основные дискурсивные практики в период пандемии и трансформацию передаваемых ими смыслов. По итогам исследования ученые построят модель риск-коммуникации с учетом интересов разных акторов и разработают рекомендации по снижению негативных последствий крупных социальных потрясений для человека.
Проект «Риск-коммуникация в сфере здравоохранения в условиях инфодемии: трансформации смыслов в социально актуальных дискурсах» поддержан грантом Российского научного фонда.

По словам руководителя проекта, заведующей кафедрой общей, компьютерной и когнитивной лингвистики филологического факультета ТГУ, профессора Зои Резановой, феномен пандемии заострил проблему коммуникативного ответа человека и общества в целом на социальные изломы. При этом в риск-коммуникациях один и тот же человек является актором одновременно нескольких дискурсов – социальных и личностных. Ученые предположили, что в таких условиях коммуникативный ответ человека будет похожим, но в результате разрывов потоков передаваемой информации смыслы будут трансформироваться.
– Мы выбрали три базовых дискурса. Первый – деловой медицинский дискурс, куда входят официальные документы, извещающие население и социальные институты о сути происходящих событий и дающие их государственную квалификацию. Он безоценочный и безэмоциональный, его информационный поток направлен неопределенному адресату, – поясняет Зоя Ивановна. – Второй дискурс – это медиа. Они связывают государство с населением и социальными институтами, интерпретируют официальную информацию и адаптируют ее определенным образом в условиях риск-коммуникации. Источником третьего изучаемого дискурса – личностного – стал Twitter, где люди персонально реагируют на происходящие события и официальные решения.
К настоящему времени лингвисты исследовали деловой медицинский дискурс. Они проанализировали тексты официальных документов на сайтах Минздрава России и Роспотребнадзора за период с 1 марта по 1 сентября 2020 года. В полученном датасете из 47 292 слов изучили доминирующие слова и частоту их употребления, фреймовые связи между понятиями. В проект вошла также часть результатов исследований новостного медицинского дискурса, полученных аспиранткой филологического факультета ТГУ и участницей проекта Екатериной Тагиной-Плешковой в ходе работы над диссертацией по схожей тематике.
Личностный дискурс был проанализирован на основе текстов микроблогов платформы Twitter: твиты, ретвиты и перенаправленные сообщения на тему коронавирусной инфекции за март 2020 года – в период пика активности участников платформы. Датасет составил 784 597 слов.
Предварительные результаты по материалам делового медицинского дискурса и коммуникации в Tvitter показали существенное различие как в тематической фокусировке, так и в базовых номинациях и их типовых связях, говорит Зоя Резанова.
– При анализе ярко была проявлена своеобразная трехъядерная структура тематического доминирования в официальном дискурсе (документная регламентация ситуации пандемии – система правоприменения – научные исследования), представленные через терминологическую лексику. Одноядерная тематическая структура в Tvitter – пандемия в ее проекции на человека – представлена через базовое слово «коронавирус», его синонимы и наиболее значимые социальные последствия – карантин, – добавляет руководитель проекта.
Сейчас команда проекта анализирует новостные медиа федерального и регионального уровня и сообщения Twitter. Следующим этапом станет моделирование образа риск-коммуникации в условиях социальных сломов и подготовка рекомендаций для акторов.
В своей работе лингвисты ТГУ, наряду с традиционными лингвистическими методами описательной лингвистики, используют междисциплинарные методы когнитивного моделирования и методы анализа больших данных и математического моделирования. Среди них методы SNА (social network analysis), тематического моделирования (вариант LDA (латентное размещение Дирихле), основанного на теория аддитивной регуляризации (ARTM), построения семантических связей и другие. Это позволяет точнее провести необходимые исследования и анализ онлайн-источников.
В проекте участвуют заведующая кафедрой общей, компьютерной и когнитивной лингвистики ФилФ ТГУ Зоя Резанова (руководитель проекта), заведующий научно-исследовательской лабораторией «Когнитивные исследования языка» Андрей Степаненко, аспирантка ФилФ Екатерина Тагина-Плешкова, лаборант лаборатории лингвистической антропологии ФилФ Юлия Сыпченкова.
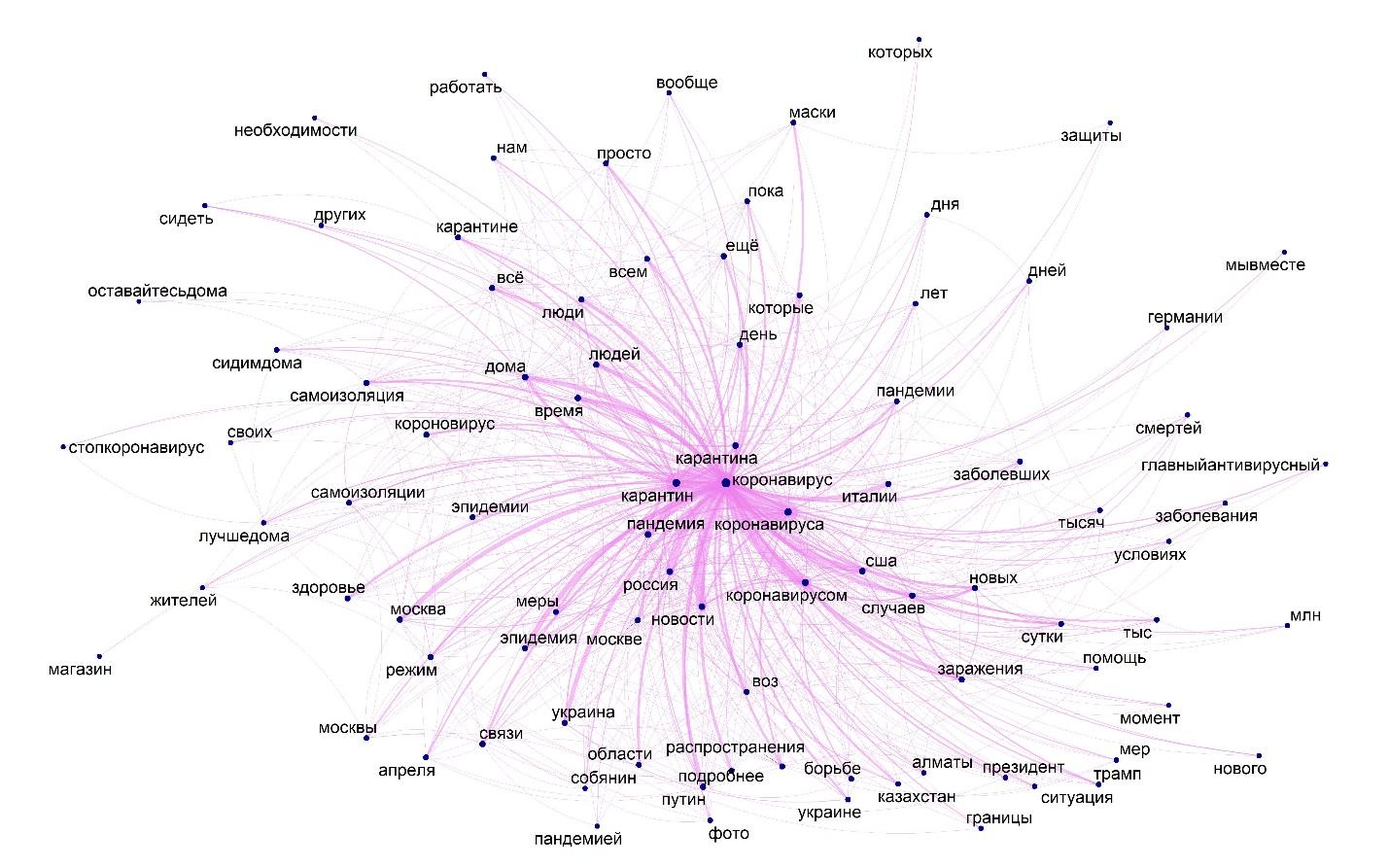
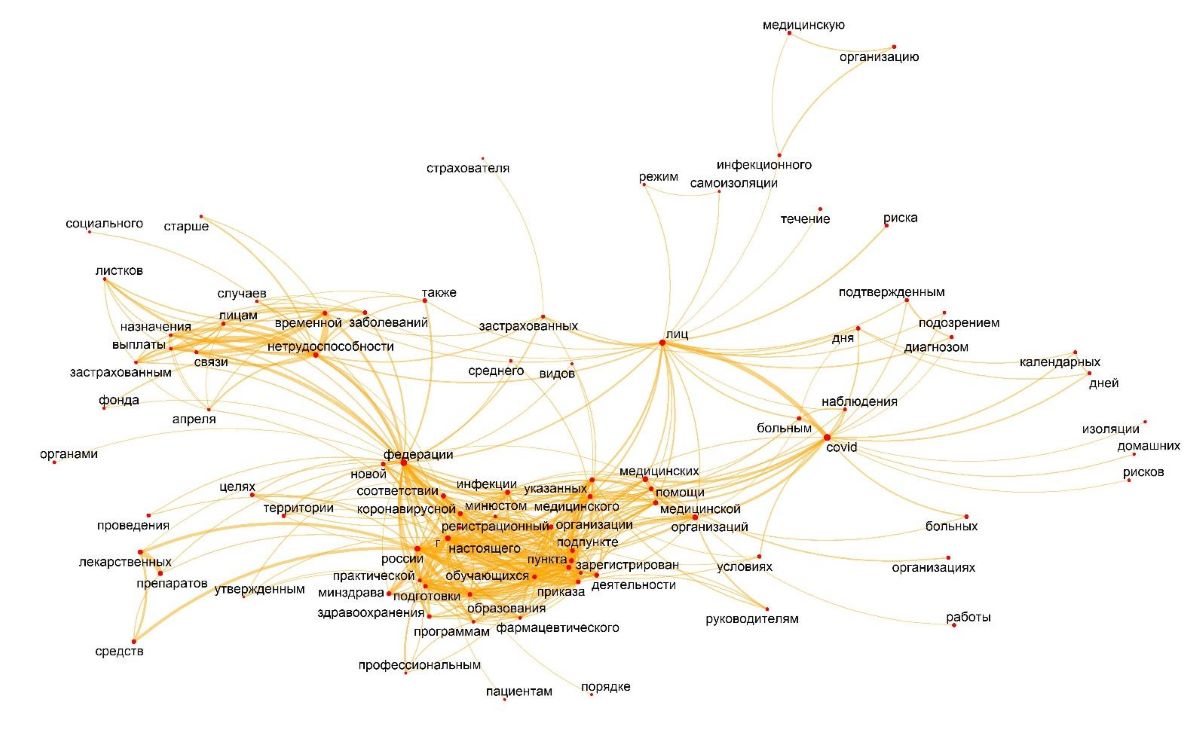
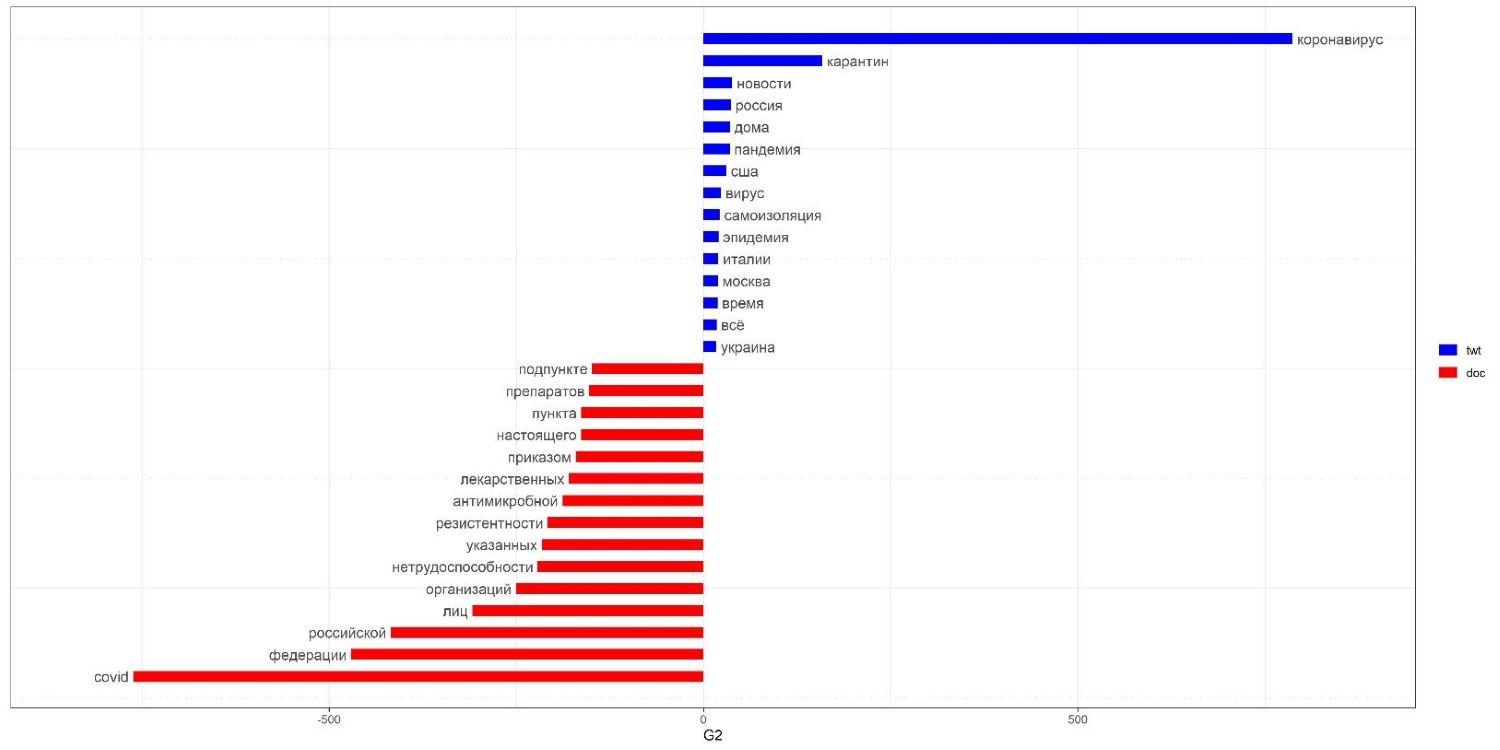
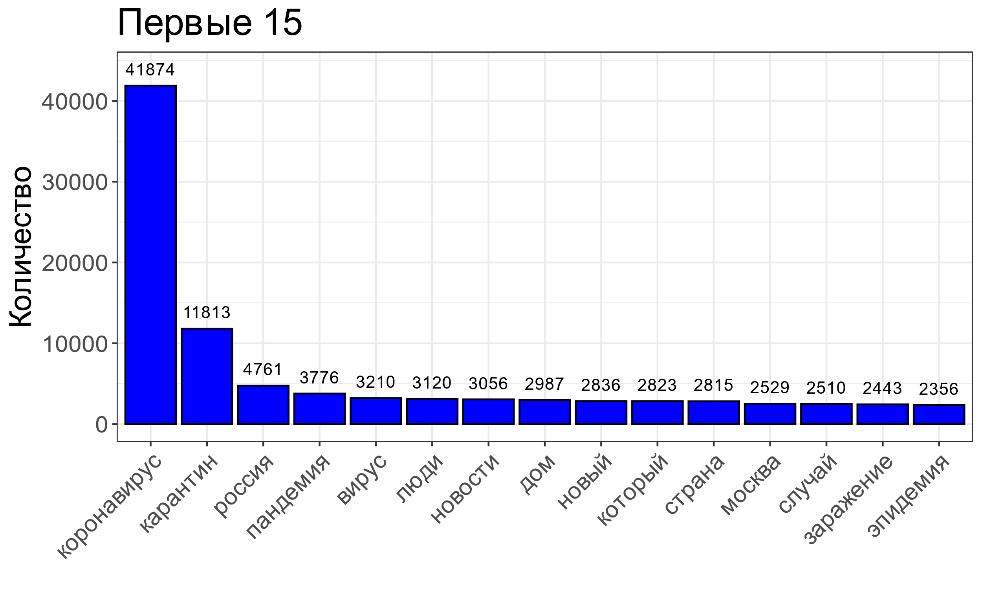
Ключевые лексемы и связи в текстах и визуализация частотности сообщений
Предоставлено сотрудниками лаборатории
Источник:Новости ТГУ